출처 : http://meetup.cloud.toast.com/posts/57
본 내용은 NHN엔터테인먼트의 김성훈 님께서 작성하신 내용 입니다.
안녕하세요. NHN엔터테인먼트 김성훈 입니다.
저번에 썼던 글을 잊어버리기 전에 올리자! 라는 생각에 부랴부랴 올립니다.
(이전글을 보고 싶으신 분들은 연재목차 를 참고 부탁드립니다.)
이번에는 MySQL 5.7 의 JSON 지원과 Native Partition 지원 같은 신규 기능에 대해서 알아보려고 합니다.
1. 복제 기능 향상
저는 다른 것 다 빼고, MSR(Mulit-Source Replication) 이 된다는것에 엄청나게 흥분했어요.
DBA에게는 정말 중요한 기능이거든요. 이게 왜 중요 하나구요? 예를들어볼께요.
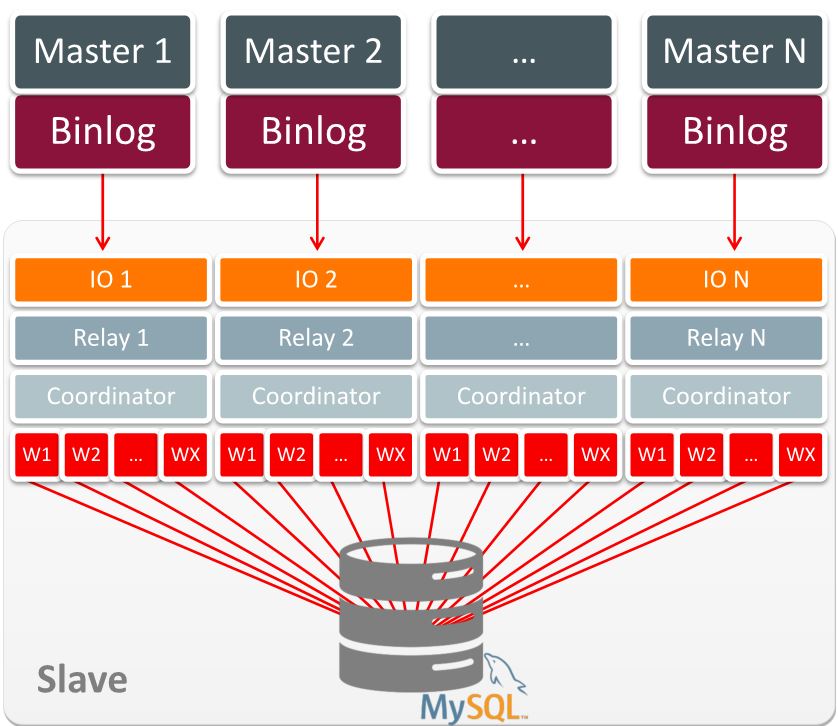
어떤 게임이 공통DB, 게임DB, 로그DB로 구성되어 있고 게임/로그DB는 여러개로 샤딩(Sharding)되어 물리적으로
다른 장비에서 서비스 해요. 그런데, 어떤 지표를 보기 위해서 모든 DB에서 한방에 쿼리를 해서 join 을 걸어야 한다면.
예전에는 batch 작업으로 특정시점에 데이터를 모두 퍼다가, 커다란 장비에 복원해야 했어요.
엄청 오래걸리고 까다롭죠. MySQL 은 복원이 특히 오래걸리거든요.
그런데, MSR이 되면? 그냥 디스크가 커다란 장비하나를 두고 모든 DB의 slave 로 붙여버리면 돼요.
그외에도 여러가지 기능향상이 있었는데. 이건 DBA 아니면 별로 관심이 없을듯 해서 그냥 목록만 적고 넘어갑니다.
- GTID 성능향상 –> 복제 깨짐을 막는데 효과 있는거에요
- Semi sync 복제 기능향상 –> 특히 slave가 여럿일 경우 더욱 향상되었어요.
- Dynamic slave filter –> 여러 DB가 있는 경우 특정 DB만 복제하기! master 변경하기! 도 쉽게 됩니다.
2. JSON 지원
다음과 같은 것들이 지원된다고 광고하고 있습니다.
- Navive JSON data type
- Built-in JSON functions
- JSON Comparator
- Indexing of Ducuments using Geenrated Columns
- New inline syntax for easy SQL intergration
여기서 가장 눈에 띄이는건 Native JSON 데이터타입과 인덱싱(Indexing)!! 입니다.
보통 text 컬럼에 json 데이터를 넣어버리면, 나중에 검색할때 모진고생을 하기 마련입니다. 데이터를 모두 읽어서 다시 파싱하고, 특정 항목을 찾아서 테이블의 별도컬럼에 저장한다음에 그 컬럼으로 인덱스 생성하고, 이제, native json 데이터타입 컬럼에 넣어두면 굳이 그럴 필요 없습니다. 처음에 데이터를 입력할 때 구조화 된 데이터 형태로 저장되고, 특정 항목을 인덱스로 추가하려고 하면 테이블의 컬럼으로 인덱스 생성하는 것 만큼이나 빠르게 인덱스로 만들어 줍니다. 물론 입력시에 validation check 해주는 건 보너스죠^^ 심지어 인덱스가 없을때도 검색이 빨라집니다.
아래는 오라클에서 시연한 화면입니다. 문법에는 신경쓰지마세요.
JSON 관련 함수중에 하나인데, JSON데이터 내에서 특정항목을 뽑아내는 기능이에요.
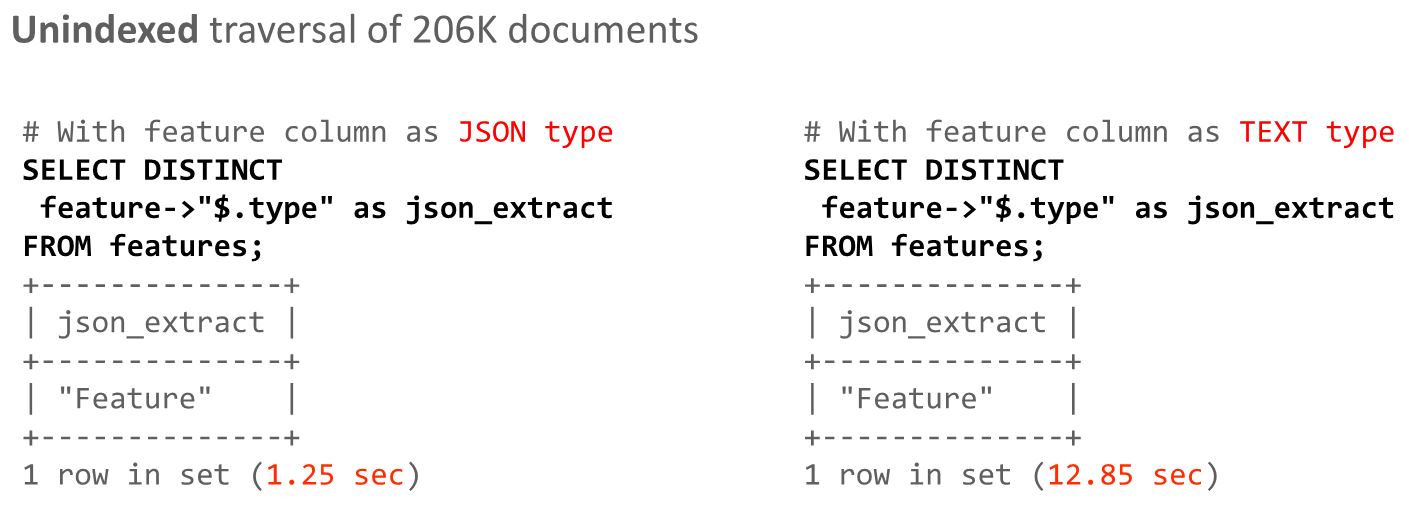
위에서 보는것처럼 10배 빠릅니다~
저 항목을 컬럼으로 빼내서 인덱스로 만들면, 저 select 문이 걸리는 시간은 0.06 sec 까지 줄어듭니다.
심지어 컬럼으로 만들고 인덱스를 생성하는데까지 걸리는 시간도 1초가 안돼요.
또, 위에서 보는것처럼 매우 잘 만들어진 함수, 마이그레이션 기능이나, 집계함수 같은것들을 제공합니다.
- Creating JSON Values / 데이터를 JSON 형식으로 만들어주고
- Normalization, Merging, and Autowrapping of JSON Values / 여러가지 형태로 가공하고
- Searching and Modifying JSON Values / 검색하고 수정하며
- Comparison and Ordering of JSON Values / 비교하고
- Aggregation of JSON Values / 집합시킬 수 있습니다.
[링크]를 참조하시면 좋을것 같습니다. 여기서 주의할점 하나. character set 이 ’utf8mb4’입니다.
3. 보안기능 향상
보안기능이 향상되었습니다. 지만 사실 조금 불편할 수도 있어요.
이해를 위해서 변경된걸 이야기 해드리는게 나을꺼 같네요.
- 패스워드 기간만료 기능추가
즉, 이제 1년이 지난 패스워드는 바꿔주셔야 합니다. 라지만, 기간만료 안 넣을 수도 있으니 너무 걱정은 마세요. - 계정 비활성화 기능추가
일시적으로 계정에 block 을 설정 할 수 있다는 이야기 입니다. - 자기 계정에 대한 패스워드 변경기능
본인 패스워드는 본인이 변경하게 되었어요 - SSL 지원이 default 가 되었습니다.
4. SQL mode 강화
사실 이게 가장 불편하실 수 있을거에요. 이제 SQL 표준에 안맞는 문법을 보다 강하게 막습니다.
ONLY_FULL_GROUP_BY, STRICT_TRANS_TABLES 가 기본으로 적용됩니다. 어디서 보신거 같으신 분 있으세요?
사실, 이건 저희 통합개발 DB에 적용된 거에요. 저희 DBA가 미리미리 적응하실 수 있게 해드렸던거죠^^
통합개발 DB를 사용하고 계셨던 분들은 그대로 사용하시면 되고, 아닌 분들은 다음 사항을 주의해주세요.
1) STRICT_TRANS_TABLES => 형식이 맞지 않는 값을 insert 할때, 예전에는 warning 이 뜨고 그냥 입력되었지만
이제 에러가 뜨고 입력안됨.
2) ONLY_FULL_GROUP_BY ==> group by 하지 않은 열을 select 할 수 없음.
5. InnoDB engine 기능 향상
Native Partitioning–> 파티션이 빨라졌습니다. 테스트 해봐야 정확하겠지만 이제 상용 못지 않아요^^- Native Full-Text Search –> 전문검색 엔진이 한글, 일본어, 중국어를 지원합니다.
- Native Sparial index
- 높은 압축률 의 페이지 압축가능
- 여러테이블을 서로 다른 디스크에 저장할 수 있습니다.
- Group Replication 지원 –> 이건 조금 이슈가 있어서 이번에는 설명 안할께요. Activ-Active 방식의 복제입니다.
- cache preloading 기능 향상 -> 부팅하고나서 캐쉬올리는데 기능이 향상되었어요
- 데이터 내용이 변경될 여지를 남겨두고 데이터를 저장하는 fill-factor 라는걸 조절할 수 있게 되었습니다.
DBA 말고는 관심 가질리 없는 기능이지만, 매우 좋은 기능이에요. - bulk load 가 빨라졌습니다! 저도 테스트 해보고 싶어요.
- 메모리가 부족하거나 남을때 InnoDB buffer pool 크기를 DB 재시작 안하고 변경할 수 있습니다.
6. Fusion IO 지원
- 디스크쓰기 할때는 정합성을 보장하기 위해서 double write buffer 라고 해서 이중으로 쓰기를 기본으로 사용합니다.
그러나 Fusion IO 에서는 이게 필요 없도록 HW에서 지원해줍니다.
NVM 이라는 형식으로 Fusion IO 디스크를 포맷하면, MySQL 은 이걸 자동으로 인식해서 보다 빠르게 동작합니다.
7. GIS 지원
- 공간데이터를 연산하고 분석할 수 있습니다. 인덱스에 R-tree 도 사용할 수 있어요. 라는데, 저희 회사에서 안쓰는
포맷이라서 사실 신경쓰기 어려워요. InnoDB 의 Native Sparial index 와 연결되는 내용입니다.
8. SYS 스키마
MSSQL 의 DMV 처럼, 시스템 상태를 보다 쉽게 알수 있게 되었습니다. 라는건데, DBA 아니면 볼일이 없는 거긴해요.
MSSQL 에서 DMV가 나왔을때의 감동을 저는 받았는데, 개발자 여러분에게 공유하기 힘들어요
이게 저한텐 참 좋은데~ 설명할 방법이 없네요 ([산수유]랑 비슷한거 같아요^^ ) 그냥 모니터링을 더 잘해드릴 수 있다고 말씀드립니다.
9. 백업도구의 강화
mysqlpump 라는 툴이 나왔습니다. 이제 ’DB를 dump 할때 multi thread 로 백업을 진행하기에 속도가 향상됩니다!’
라고는 하는데, 사실 상용툴만은 못합니다. 그래도 예전에 비하면 장족의 발전이에요.
정리하면
1. 복제는 MSR 을 포함한 기능이 많이 향상되었고, slave 가 여럿일때 더 좋아졌습니다. 한 master DB에 8개 이상의
slave DB 를 붙여도 이젠 괜찮아요^^
2. JSON 은 이제 Mysql 에 저장하세요. 다양한 함수와 쿼리, 그리고 강력한 검색기능이 있습니다.
3. 보안강화, SQL_MODE 기본 추가 같은 것은 우리를 조금 불편하게 하지만 보다 안전하게 해주죠.
4. InnoDB 의 파티션 기능도 이젠 쓸만합니다. 여러가지 자잘한 기능도 좋아졌고요.
5. Fusion IO 를 통째로 쓸 때 성능이 매우 높아졌습니다. 이제 MySQL 도 커다란 장비를 통으로 쓸 수 있어요.
6. SYS 스키마를 비롯한 관리기능이 향상되었습니다. 보다 잘 모니터링 해드릴 수 있게 되었어요.
오늘 올리는 글은 여기까지 입니다.
사실 MySQL 5.6 에서도 도입되었고 더 좋아진 Memcached API 라든가, 파티션 테이블에서 가능해진 Online DDL의 종류
같은걸 이야기드릴까도 생각했는데, 이건 다음 기회에 이야기드릴께요. 긴글 읽어주셔서 감사합니다.

Leave a Reply